AI insights for scorecards
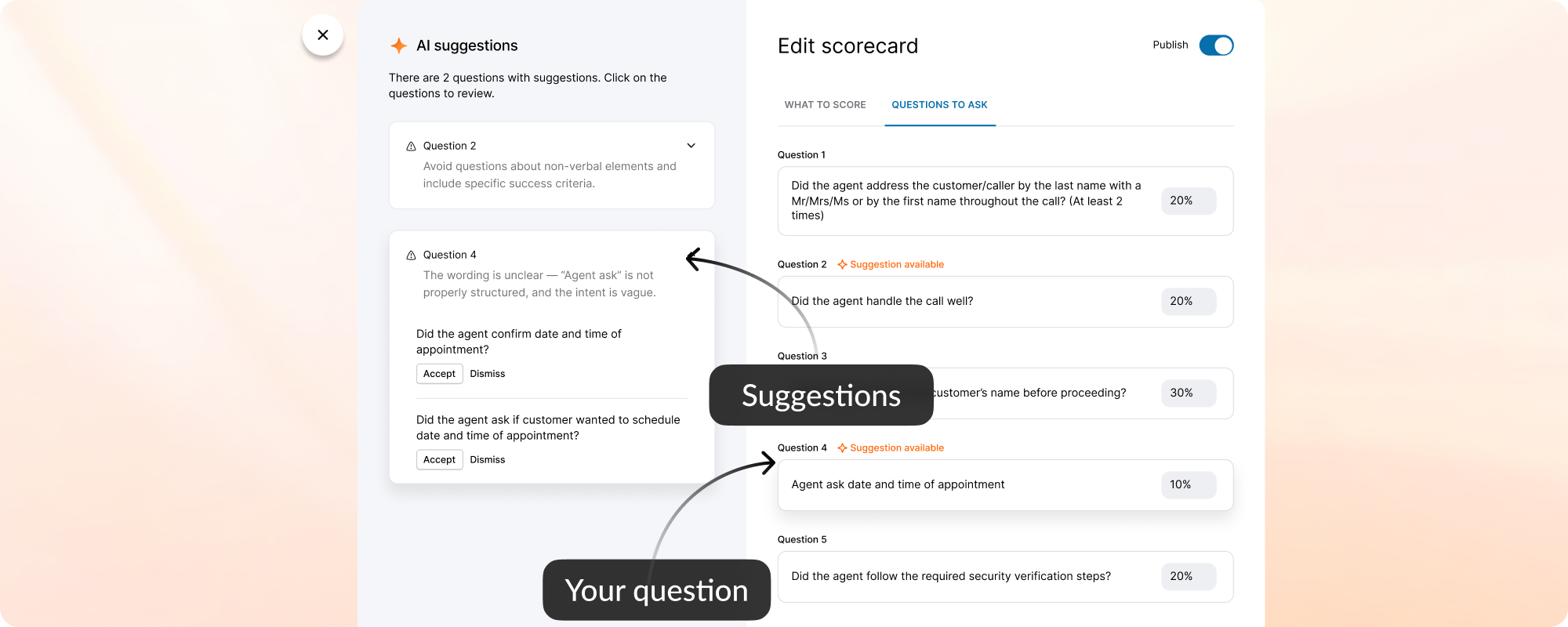
Contact center managers were drowning in manual scorecard reviews — slow, biased, and impossible to scale. I led the design of a GenAI-powered calibration system that turned a human bottleneck into an automated, high-trust workflow.
The problem
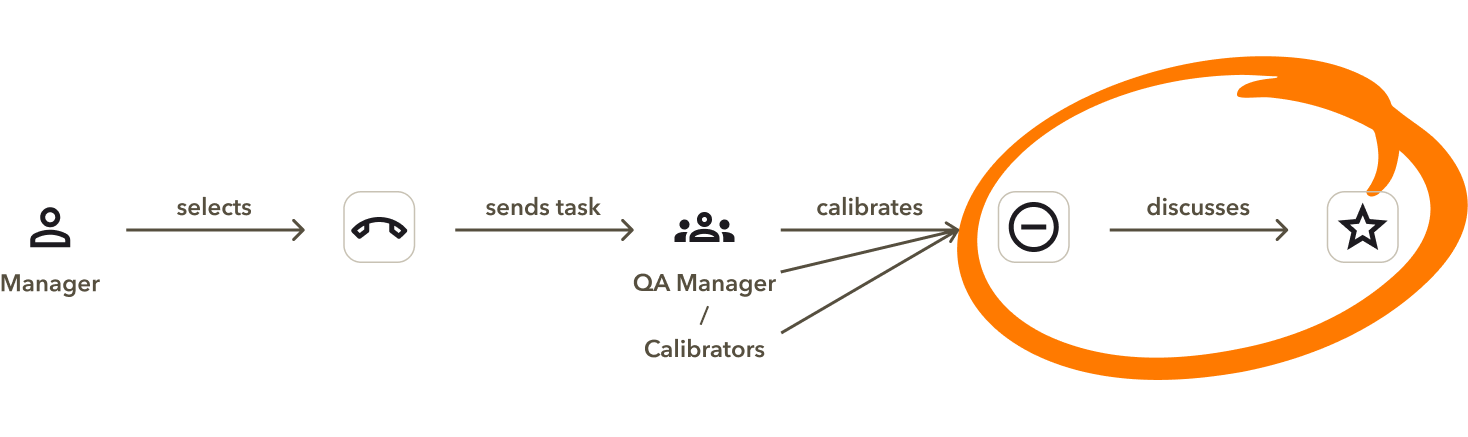
ACE — RingCentral's post-call analysis tool — lets managers define scorecards to evaluate agent performance. Traditionally, every unscored call flag required manual review. As call volumes scaled, this created an unsustainable bottleneck: slow, prone to bias, and impossible to maintain at pace.
My goal was to transform scorecard calibration from a manual chore into an automated, high-trust workflow — and in doing so, leapfrog competitors while driving down cost per resolution.
Navigating the headwinds
Three constraints shaped how I worked throughout this project. Executives had competing priorities, so I learned to arrive with a clear recommendation rather than a menu of options. A distributed team across Spain, India, and the US pushed me toward async-first documentation where every artifact needed to be self-explanatory enough to move decisions without a meeting. And a mid-project reduction in force eliminated my dedicated PM, putting me in direct contact with leadership far more often than planned — raising the stakes on every presentation I ran.
Discovery and tradeoffs
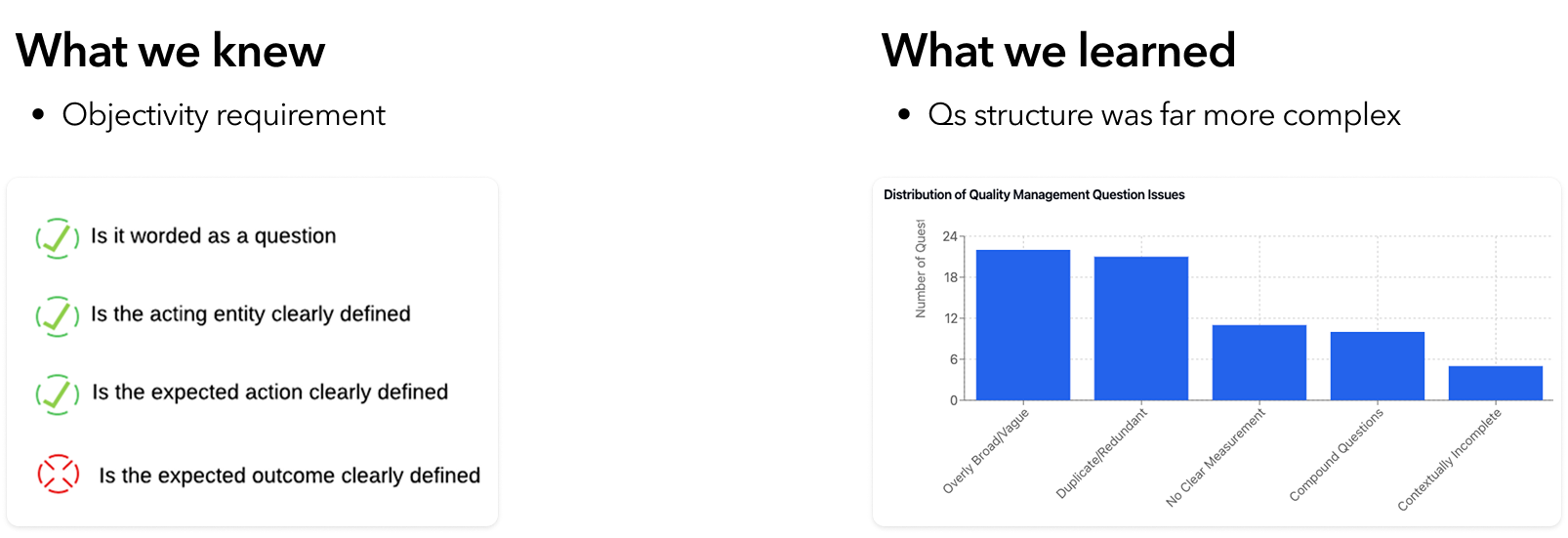
Working closely with Data Science, I found the PRD's initial framing — a simple pass/fail scorecard evaluation — didn't hold up against real use cases. Questions were more nuanced than expected, requiring the AI to understand the manager's underlying intent.
Backend conversations surfaced two key tensions:
-
1
Cost vs. latency
Evaluating an entire scorecard at once was cheaper but slower. Question-by-question was faster but more expensive. As the first AI experience in the product, minimizing cost was the priority.
-
2
Targeting vs. coverage
Targeting meant filtering noise so the AI processed only high-relevance inputs. Coverage meant keeping the model fresh as customer needs shifted — especially during fast-moving seasonal promotions.
Design approach
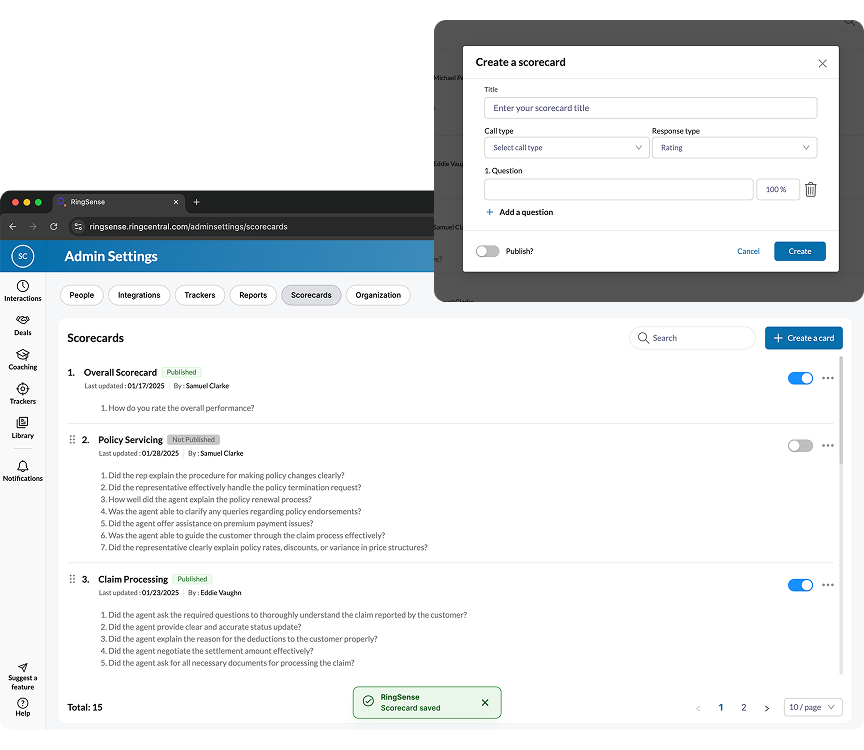
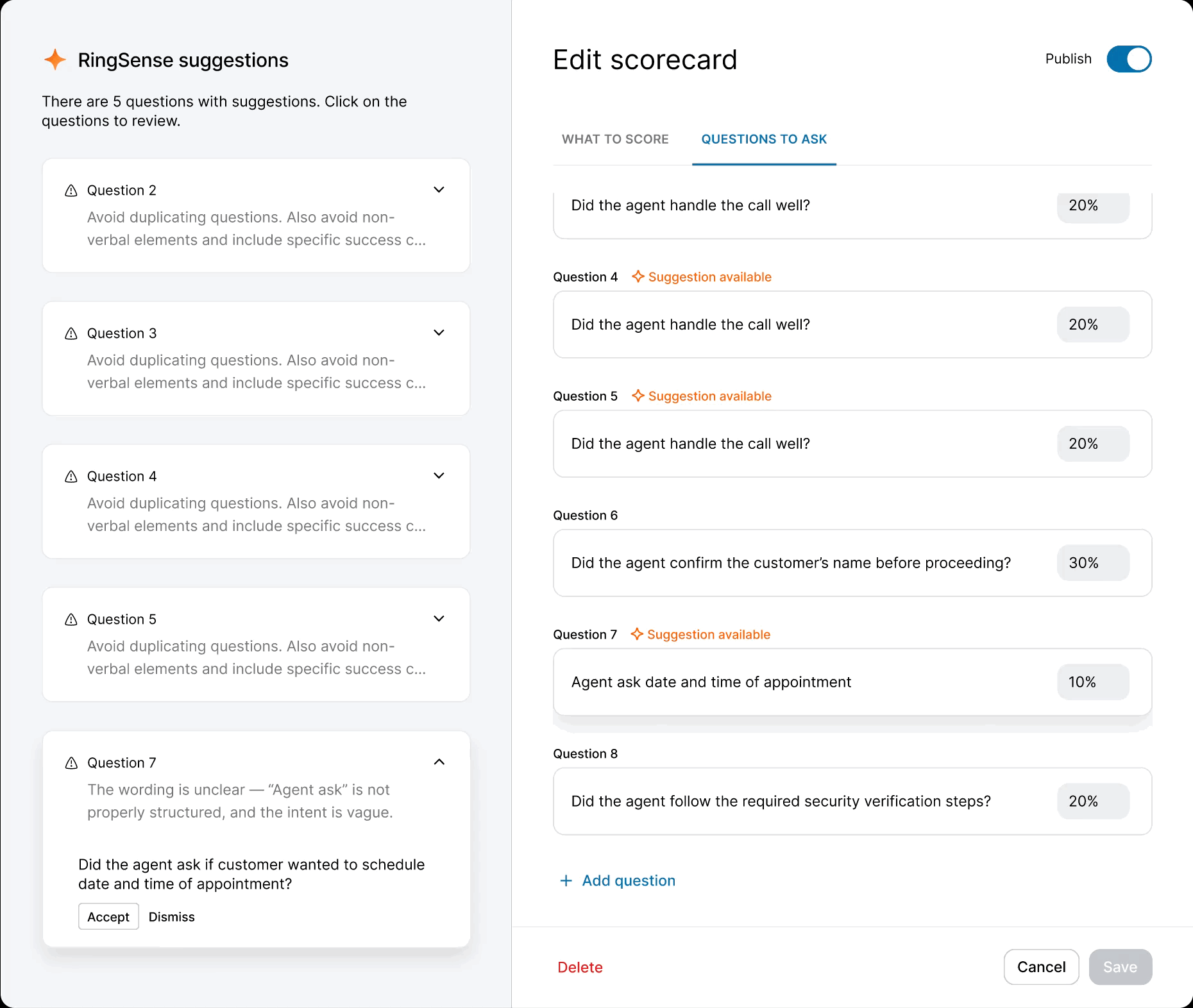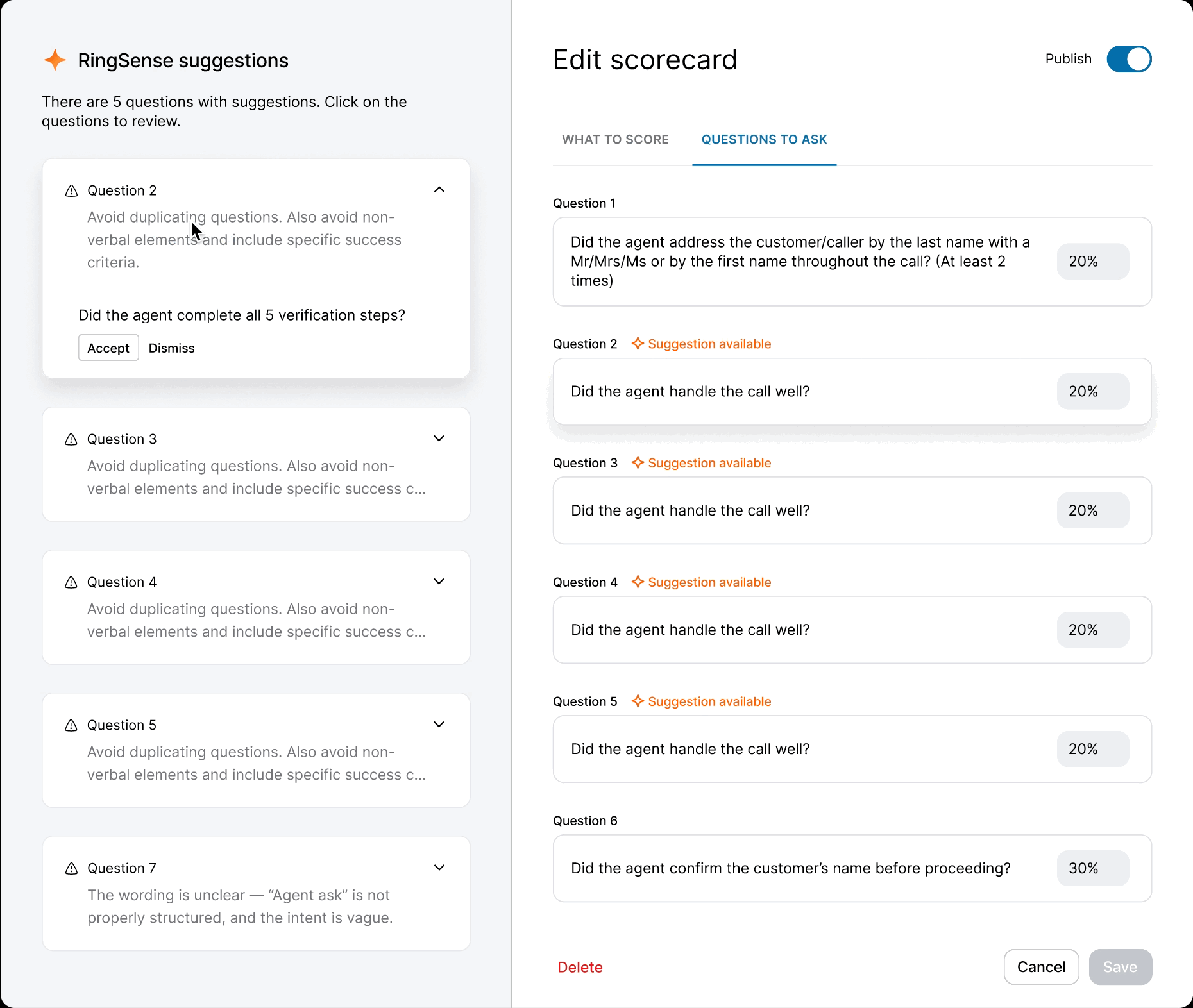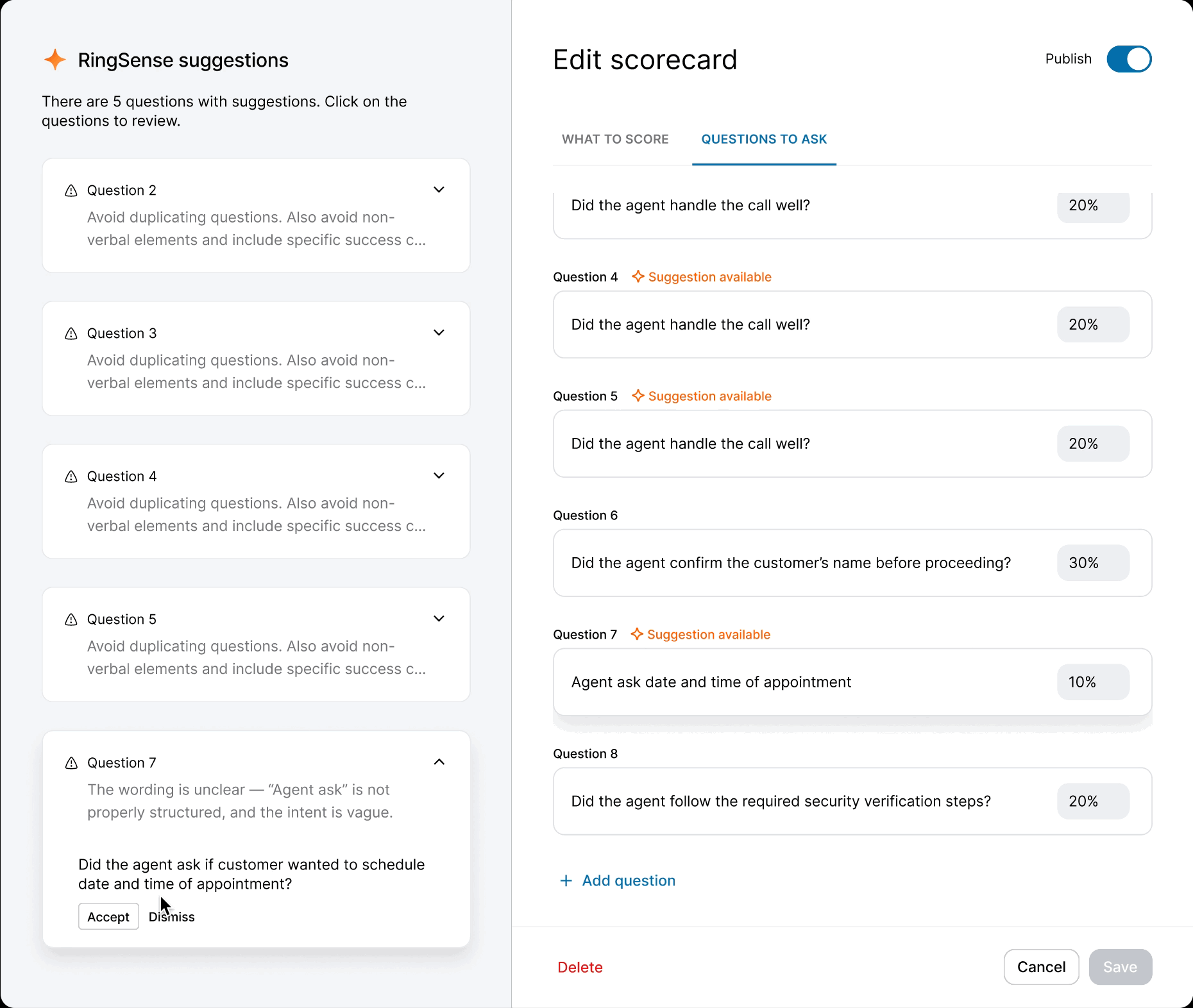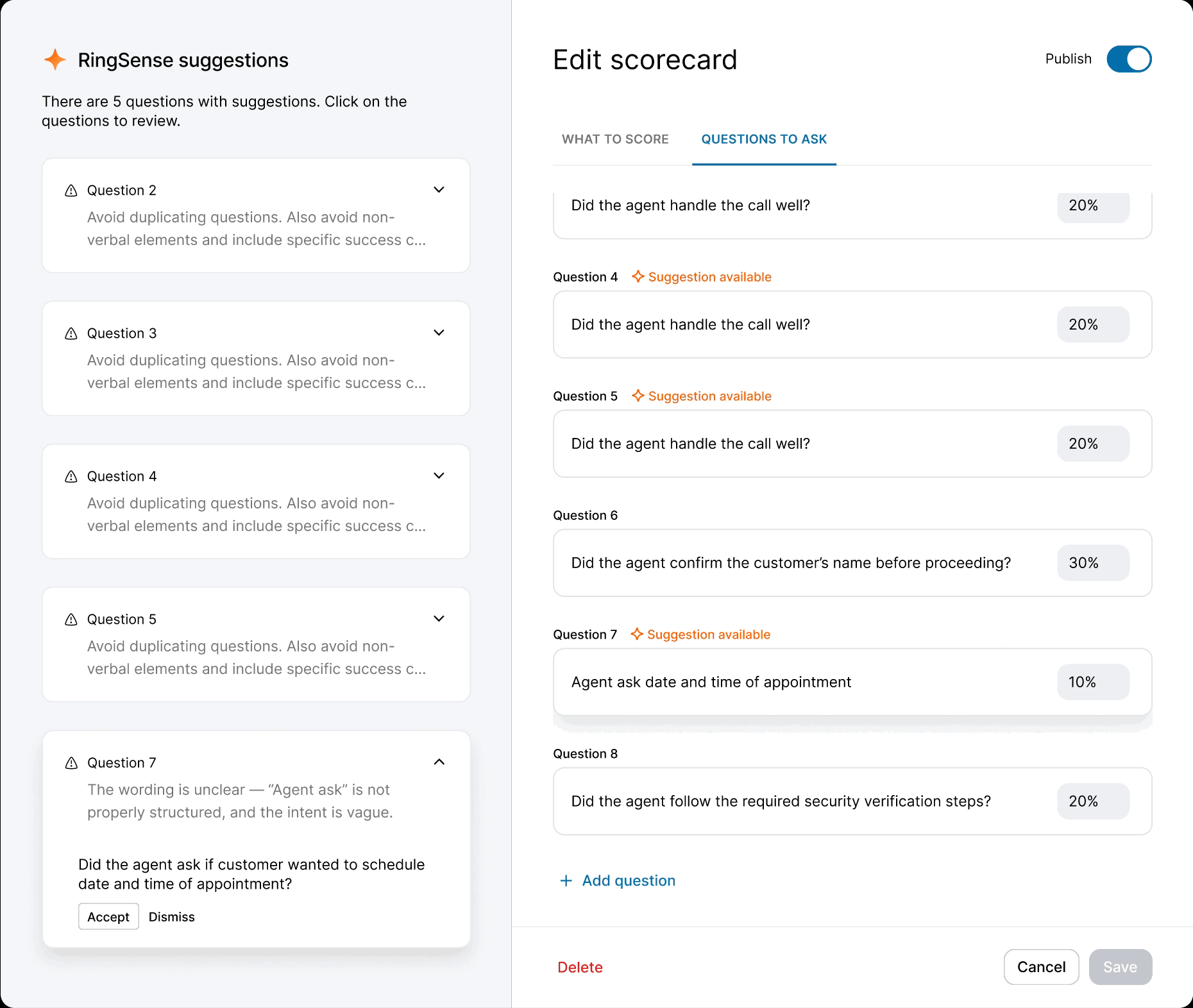
I explored two directions. The first followed the PRD: a scorecard-level evaluation tagging each question as "Strong" or "Needs Work." Testing revealed a critical gap — it diagnosed problems without prescribing solutions. A pass/fail grade without a lesson plan.
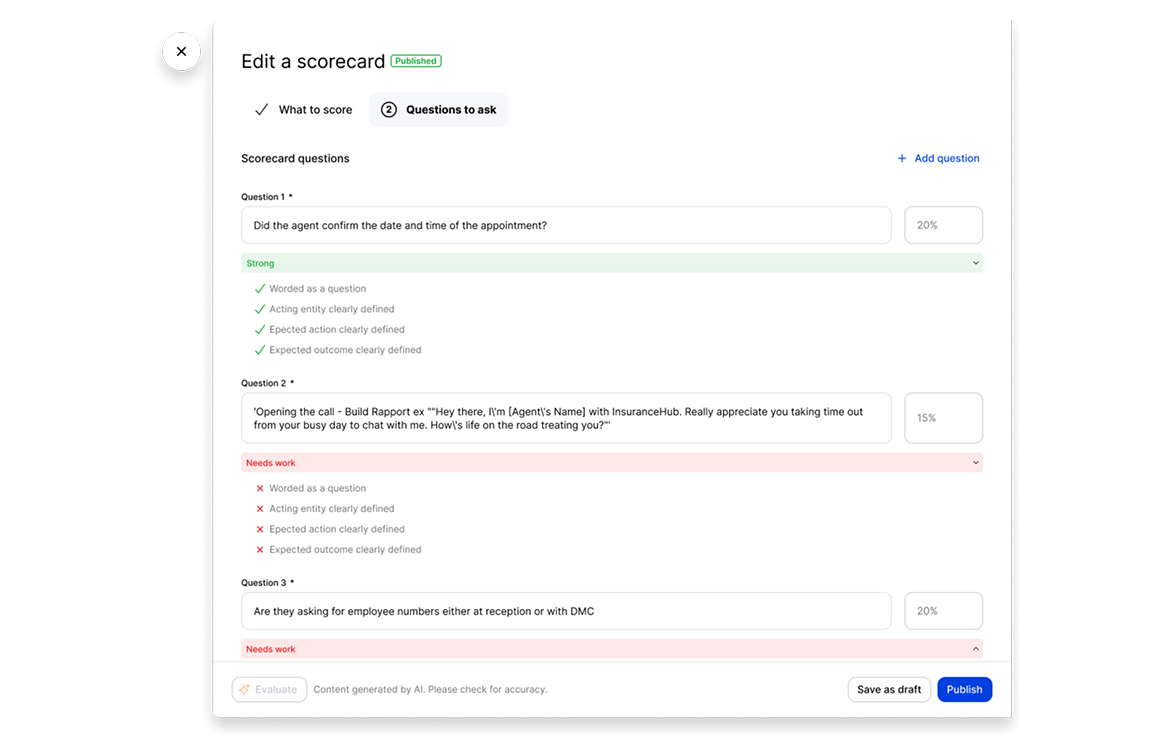
The second was more aspirational: a prompt-based approach that analyzed the manager's intent at the scorecard or question level. After alignment sessions with Product and Engineering, we landed on a hybrid — weekly, scorecard-level evaluations for the highest-traffic assets, balancing depth of analysis with low latency.
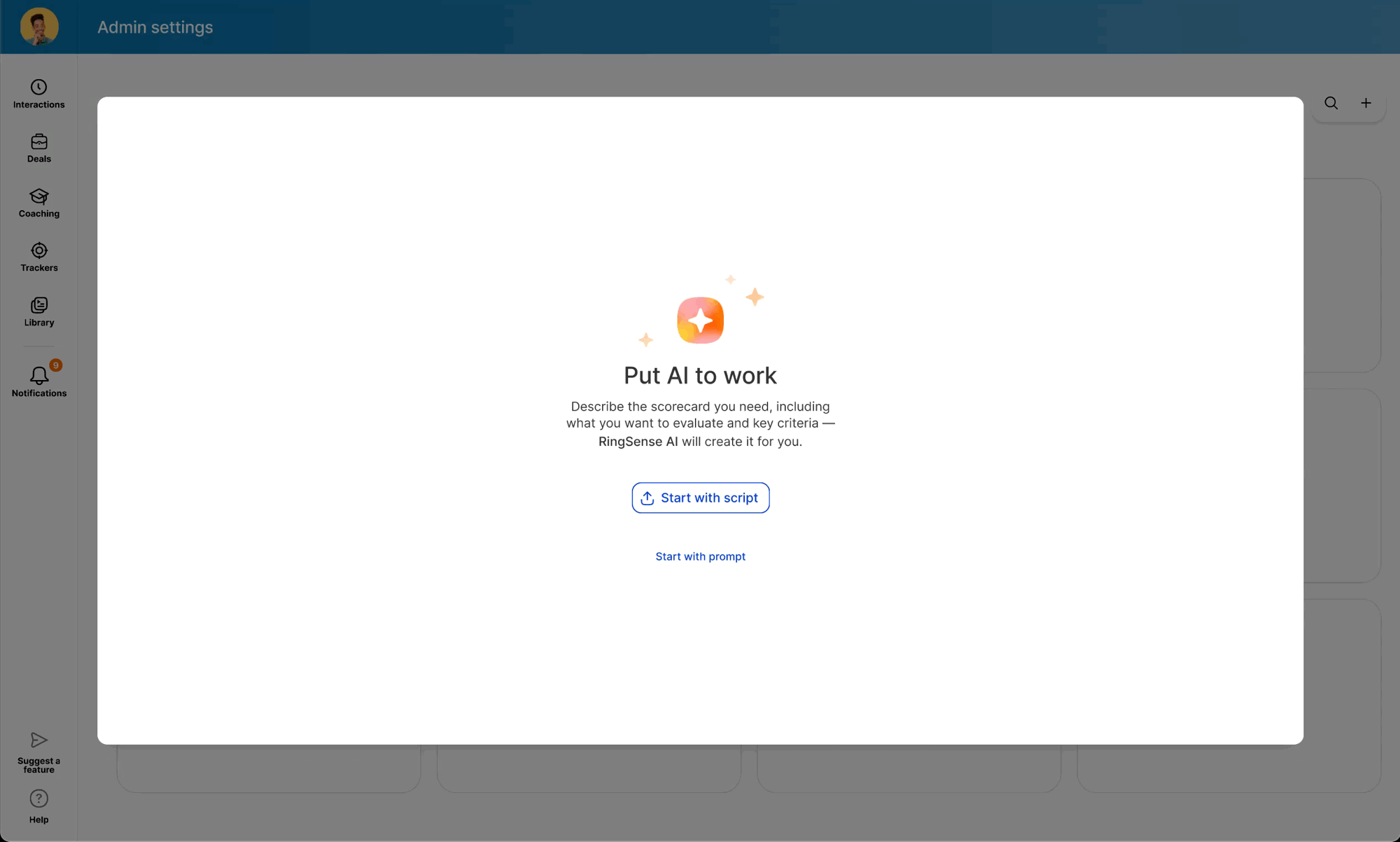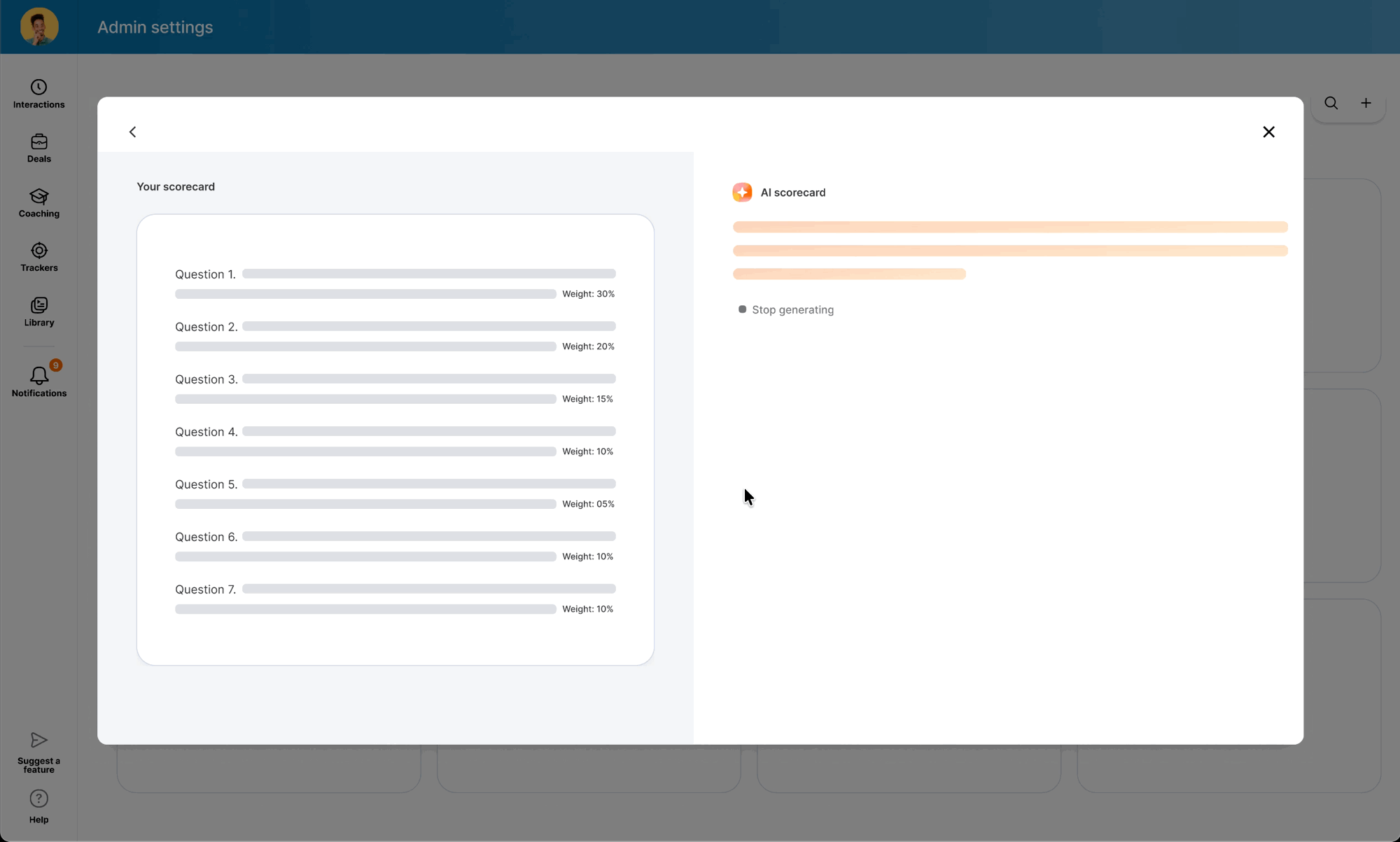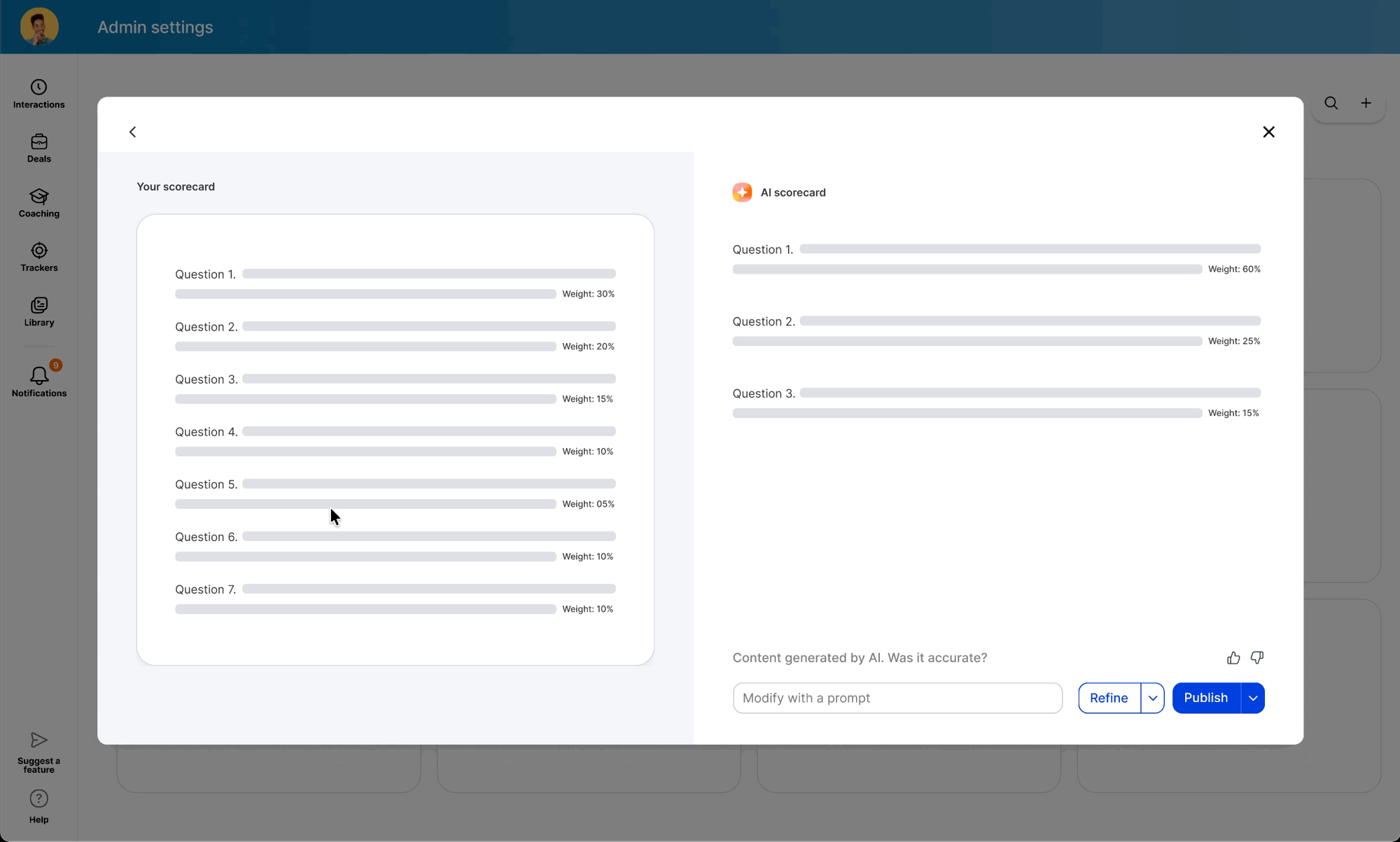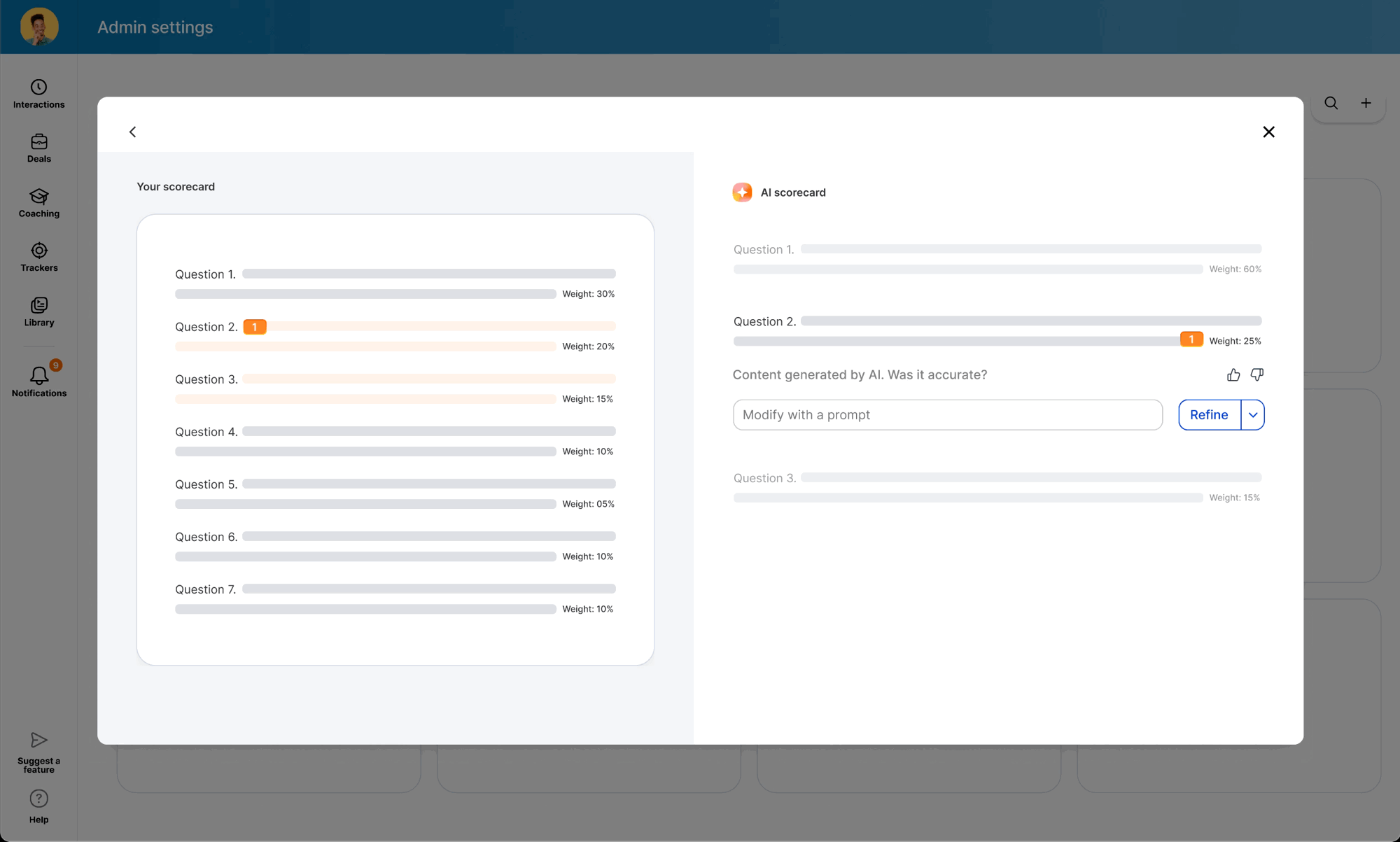
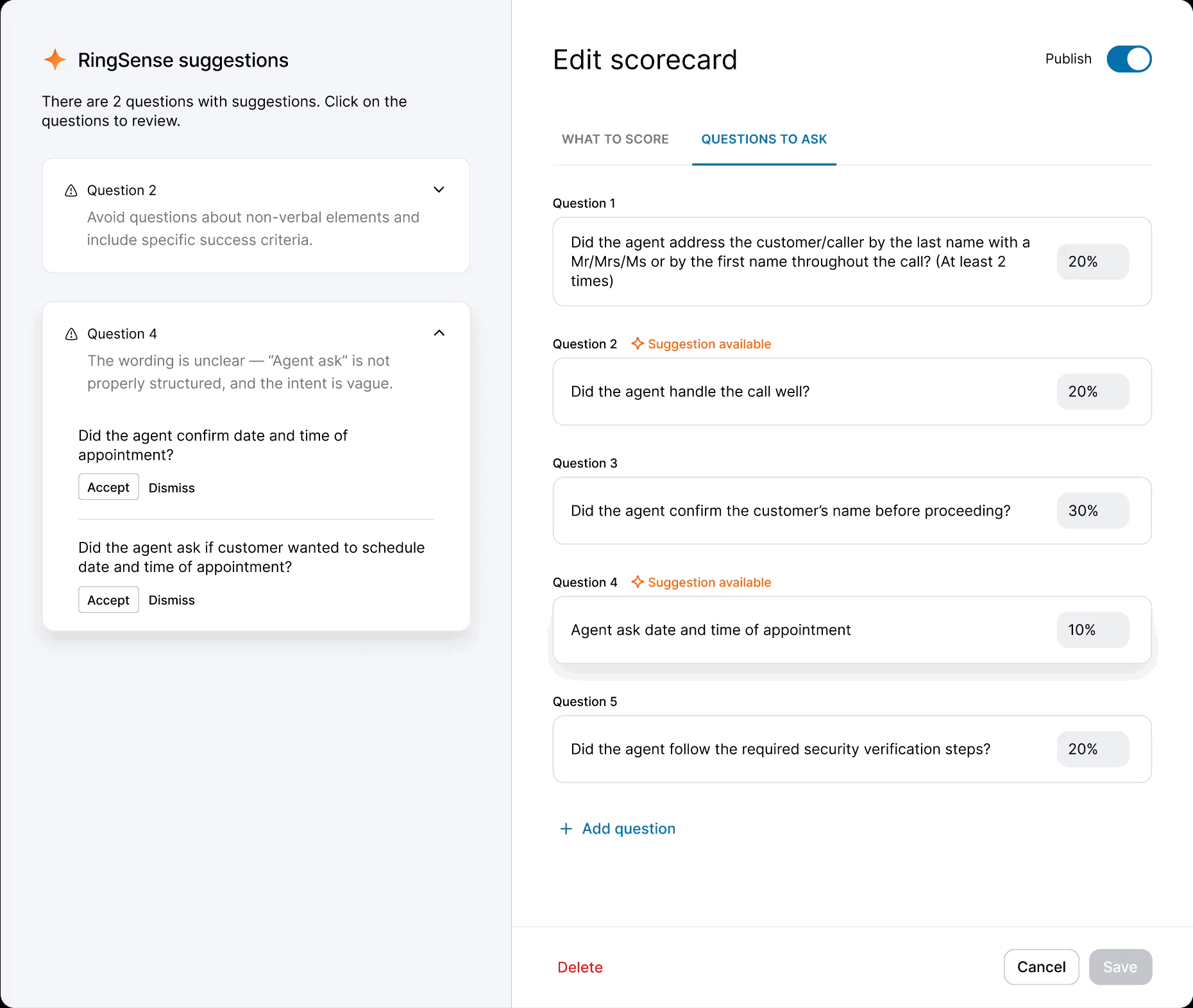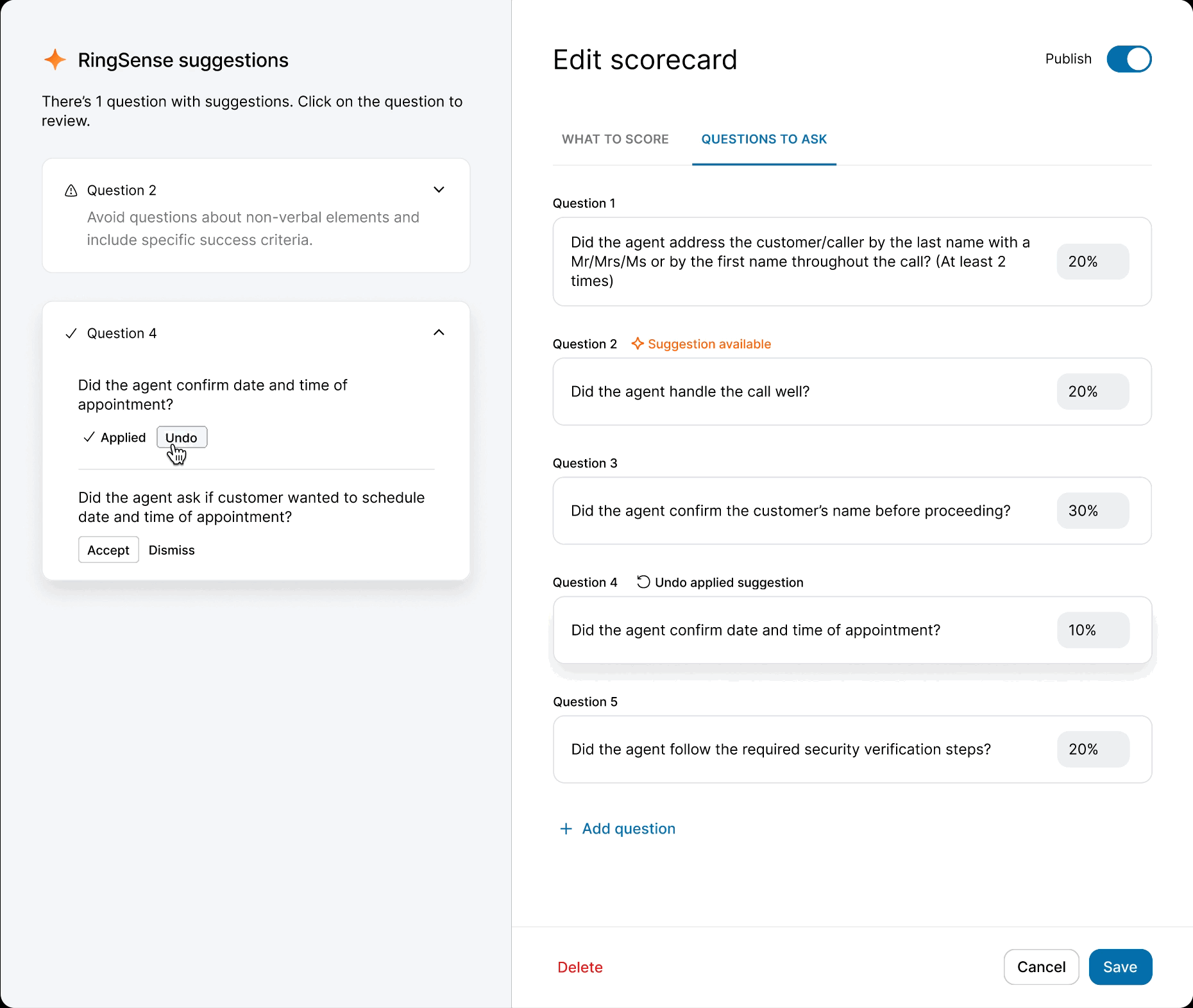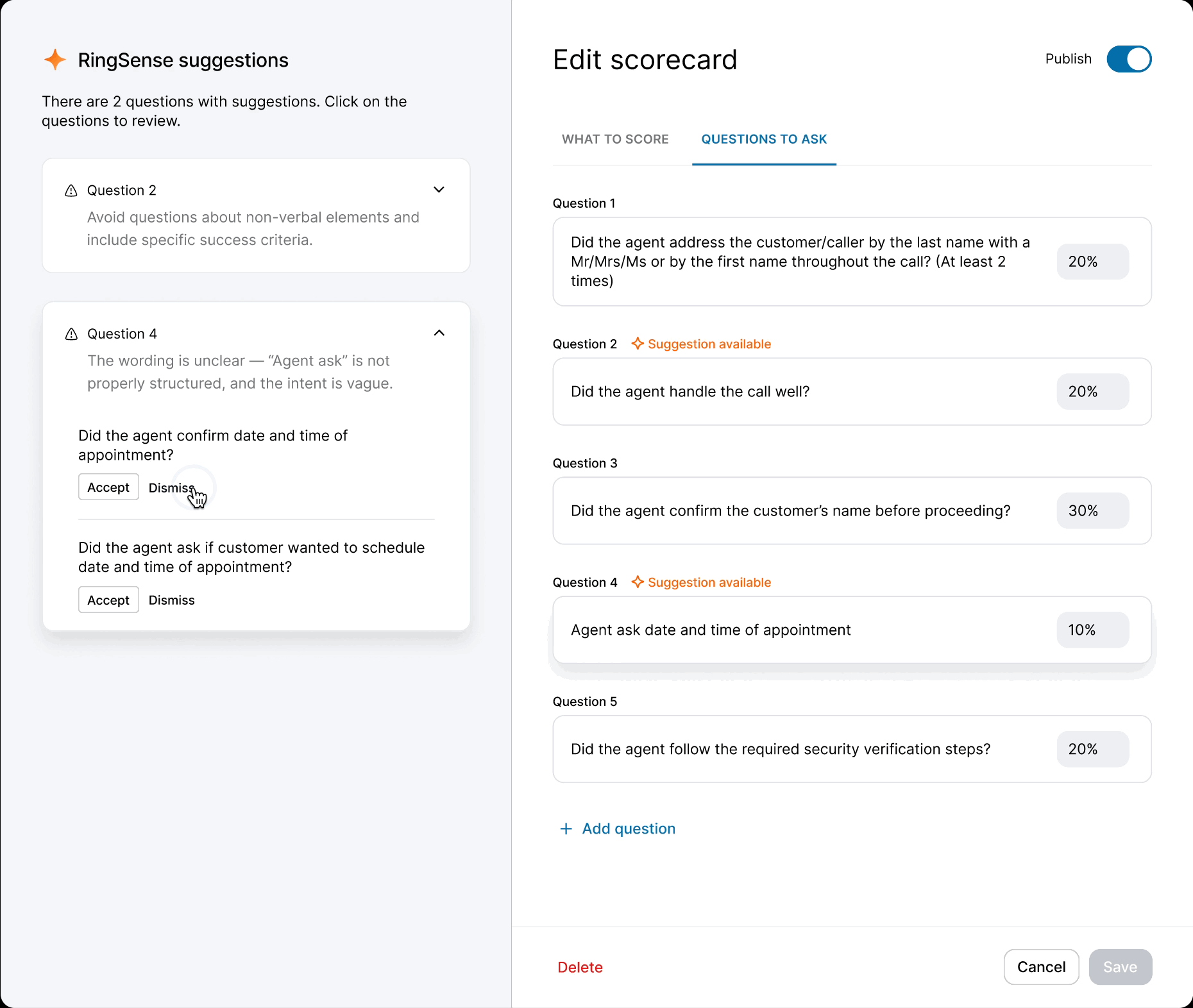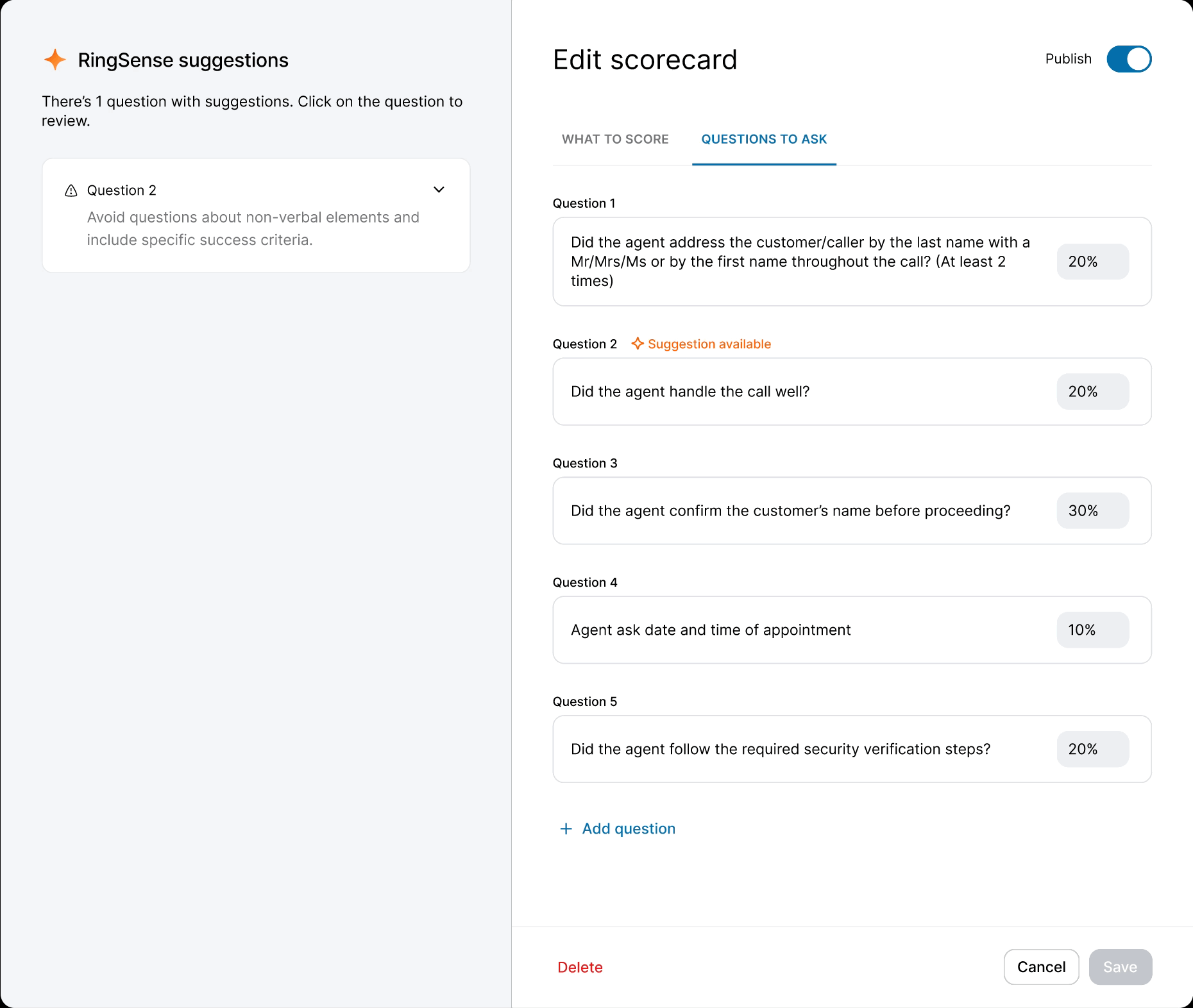
While the backend was in development, I used the time to modernize the legacy scorecard table and modal components — ensuring the AI features would launch into a polished UI. I also ran "knowledge exchange" sessions with Data Science and Content Design to translate model outputs into an in-product guide: a library of high-performing question examples managers could copy directly into their scorecards.
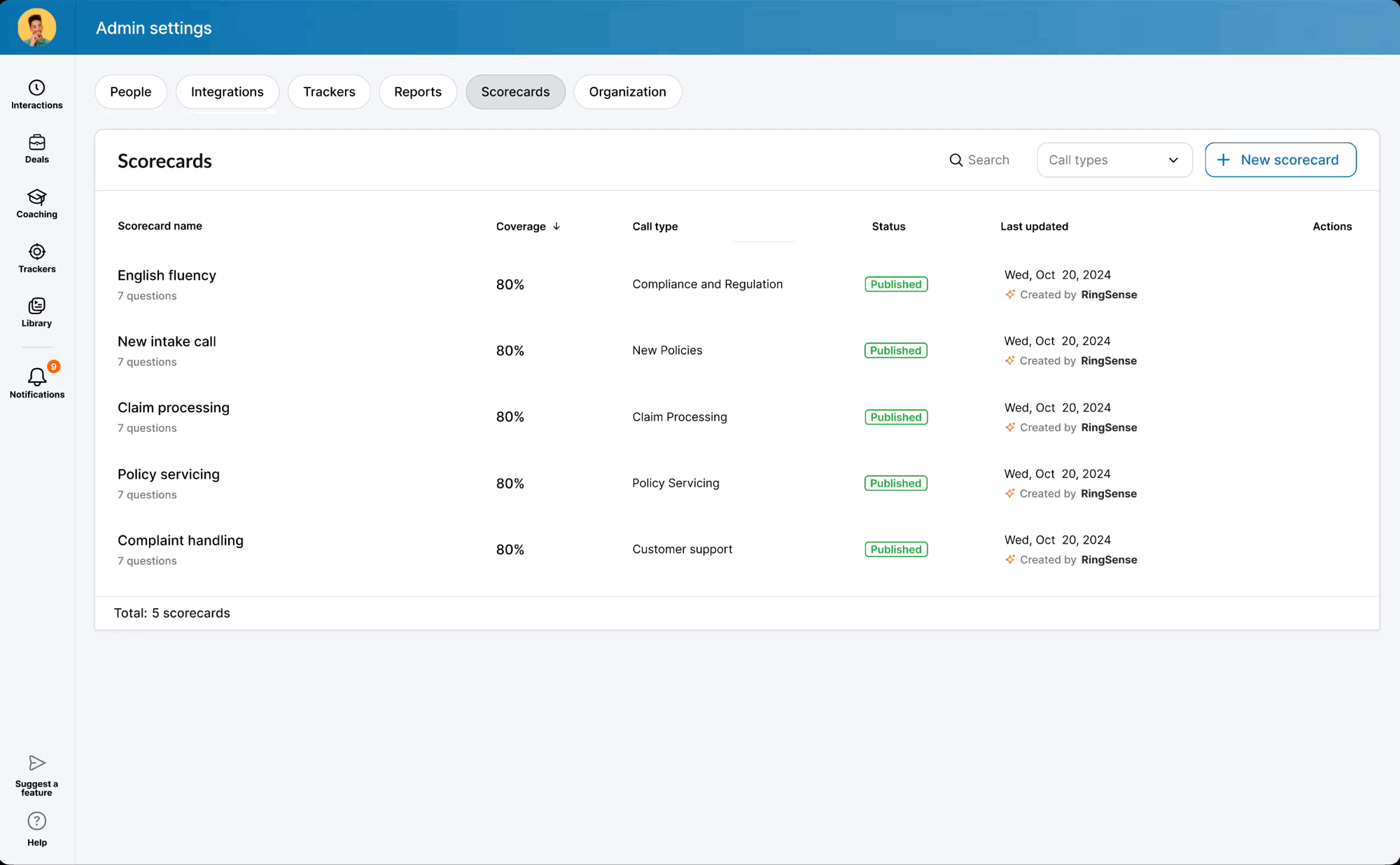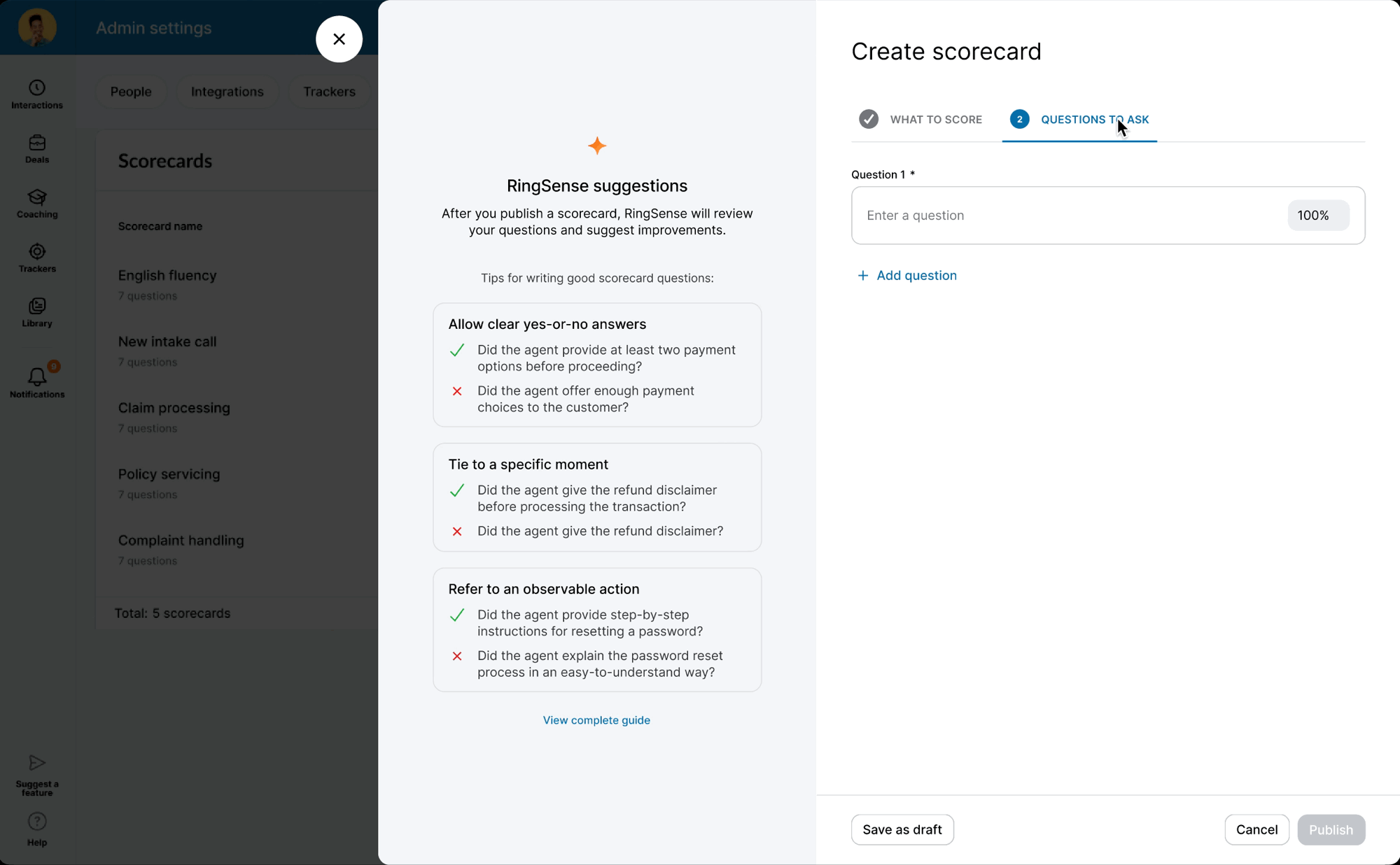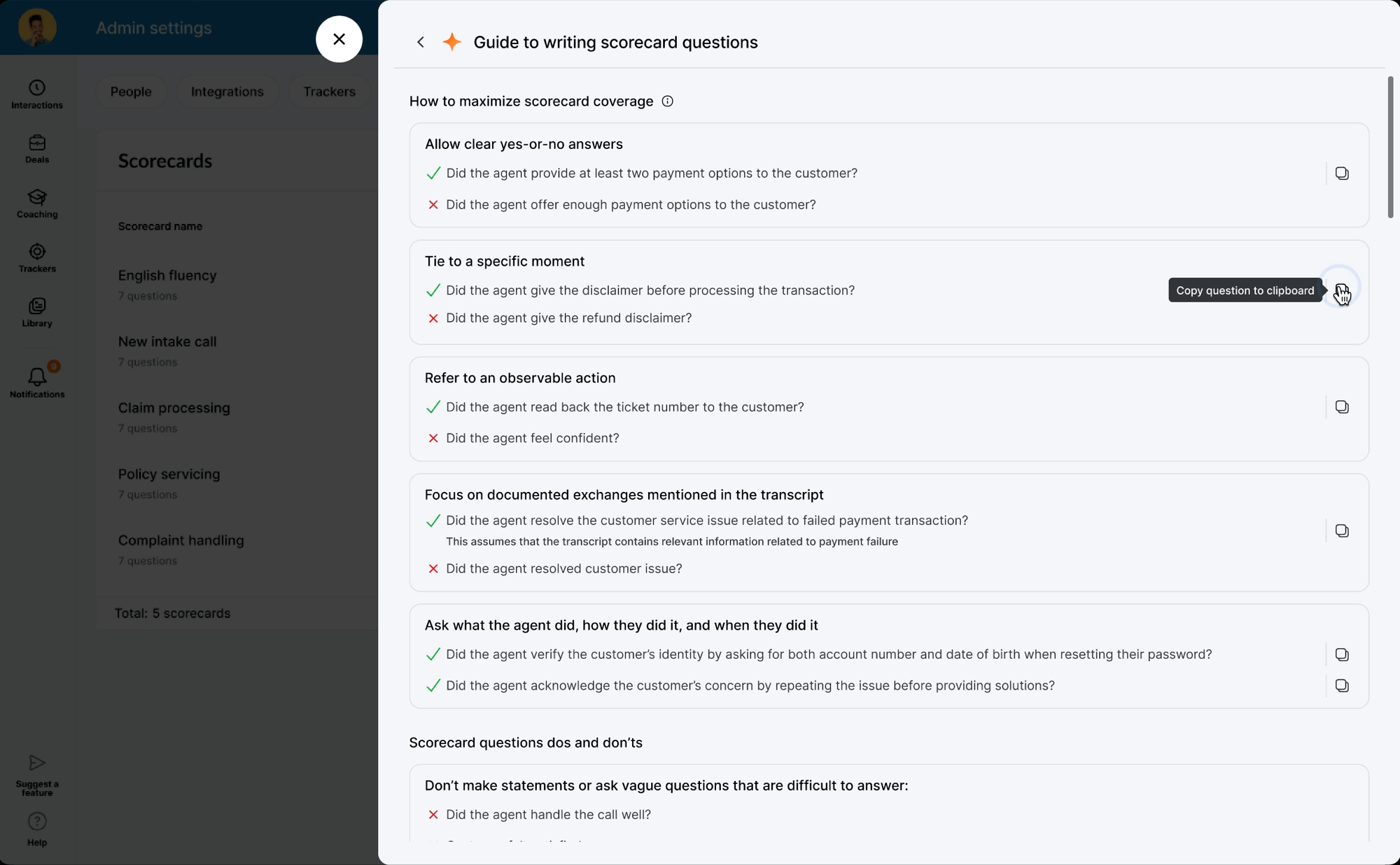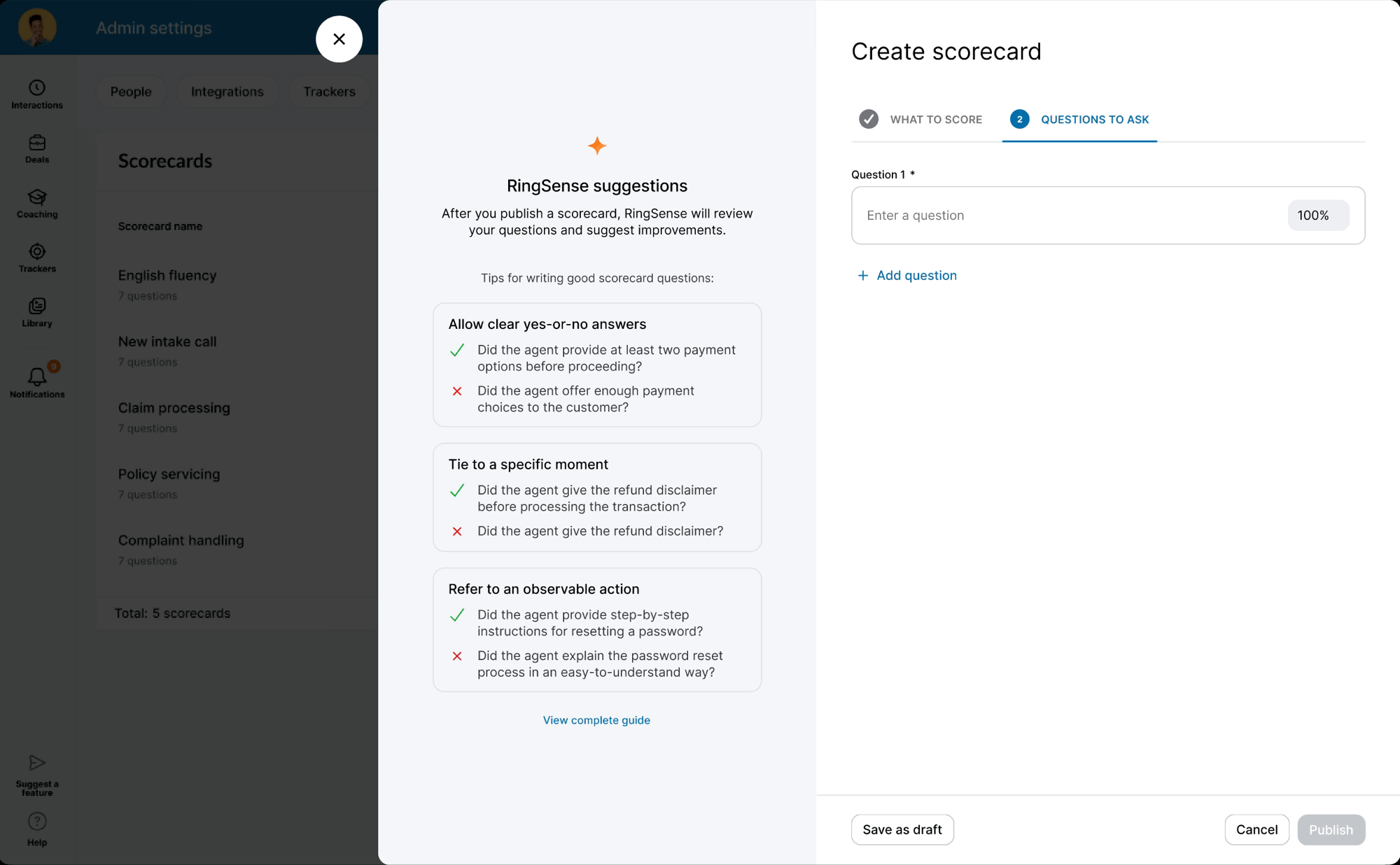
When the model was ready, I defined precise interaction details — anchor scrolling between AI suggestions and text fields, and Accept/Undo/Dismiss actions treated as signals for model refinement. I also eliminated the manual weight calculation burden by implementing auto-balancing logic, removing the cognitive load of keeping scorecards totaled to 100%.
Outcomes
Post-launch data confirmed the feature had become a daily workflow staple. Consistent scorecard scores paired with faster iteration cycles meant quality and velocity improved together — without adding headcount.